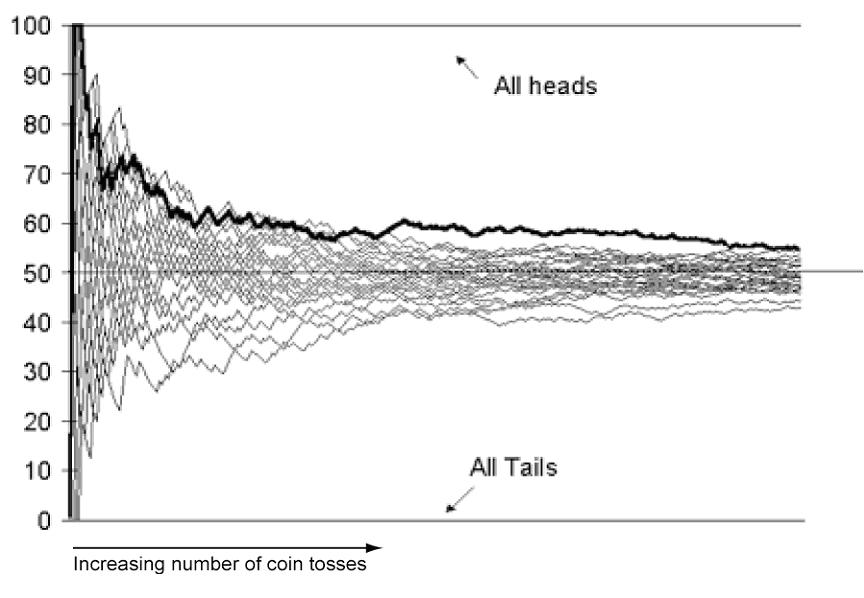
First, let’s illustrate the law of large numbers. If you flipped a coin 10 times, you should expect to get 50% heads. However, this may not happen. You could get anything from 0 to 10 heads. The most likely outcome is flipping 5 heads, and the odds of this outcome is 50%. Variations from this become increasingly less probable. For example, the odds of you flipping 4 or 6 heads is 26%, and the odds of you flipping 3 or 7 heads is 10%. Now, let’s say you flipped a coin 100 times. The odds of getting exactly 50% heads is still 50%. But, do you think the odds of getting 60 heads is also 26%? It’s actually only 2%. It’s much easier to get 6 out of 10 heads, than it is to get 60 out of 100 heads. What are the odds of flipping 600 heads out of 1000 flips? It’s 0.00000001%. With 1000 flips, you’re pretty much always going to get around 48%-52% heads. Deviations beyond that range are very improbable. So, in summary, the law of large numbers states that the more trials you have, the closer your actual outcome will be to the theoretical expected probability (In this case, the more coins you flip, the more you’ll start to approach actually getting 50% heads)

So, how does this tie into casinos? Let’s take the roulette wheel as our example. There are 37 total numbers. 18 reds, 18 blacks, and 1 green. If you guess red or black correctly, you’ll get a 1:1 payout (ie: If you bet $1, you’ll get back $2, thereby winning $1). If the wheel lands on green (0), both red and black lose. This is where the casino gets it’s edge in this particular gamble. Let’s calculate the expected value of a $1 bet on red.
\(E[X] = \frac{18}{37}(\$1)+\frac{18}{37}(-\$1)+\frac{1}{37}(\$-1) = -\$.03\)
What this means is you have an 18/37 chance of winning $1 (if it lands on red), and 18/37 chance of losing $1 (if it lands on black), and a 1/37 chance of losing $1 (if it lands on green) The expected profit for playing this game is negative 2 cents. Now, sometimes you’ll win, and sometimes you’ll lose, but if you play enough times, you’ll be averaging a loss of 23 cents per round. This is where the law of large numbers comes into play. As long as enough people are playing, the house will be averaging a profit of 2 cents for every dollar bet on that roulette table.
Question: What is the expected value of correctly guessing a specific number? There are 37 numbers, but the payout is 35:1 (You get paid $35 for each dollar you bet) Based on this answer, is it smarter to try guessing the color or guessing the number?







 http://www.livestrong.com/article/87496-size-snowboards/
http://www.livestrong.com/article/87496-size-snowboards/









